How I built my first side project: Tubee, in 2017
no AI, just SSH, Stack Overflow, and pure stubbornness
This is the story of my first side project—a journey of discovery, frustration, and ultimately, some valuable lessons learned.
What?
As a CS college student, watching YouTube videos was part of my daily routine. This was around the time YouTube began transitioning from a simple video hosting platform to a social network. Naturally, people became skeptical about the recommendation algorithms. That’s when the basic idea formed: a YouTube feed that I could actually trust.
I also wanted to answer a specific question:
Does YouTube strategically withhold notifications for new videos from subscribed channels to prevent attention fatigue?
More broadly, I aimed to develop a solution that would not only answer this question but enhance the entire experience of discovering and consuming YouTube content.
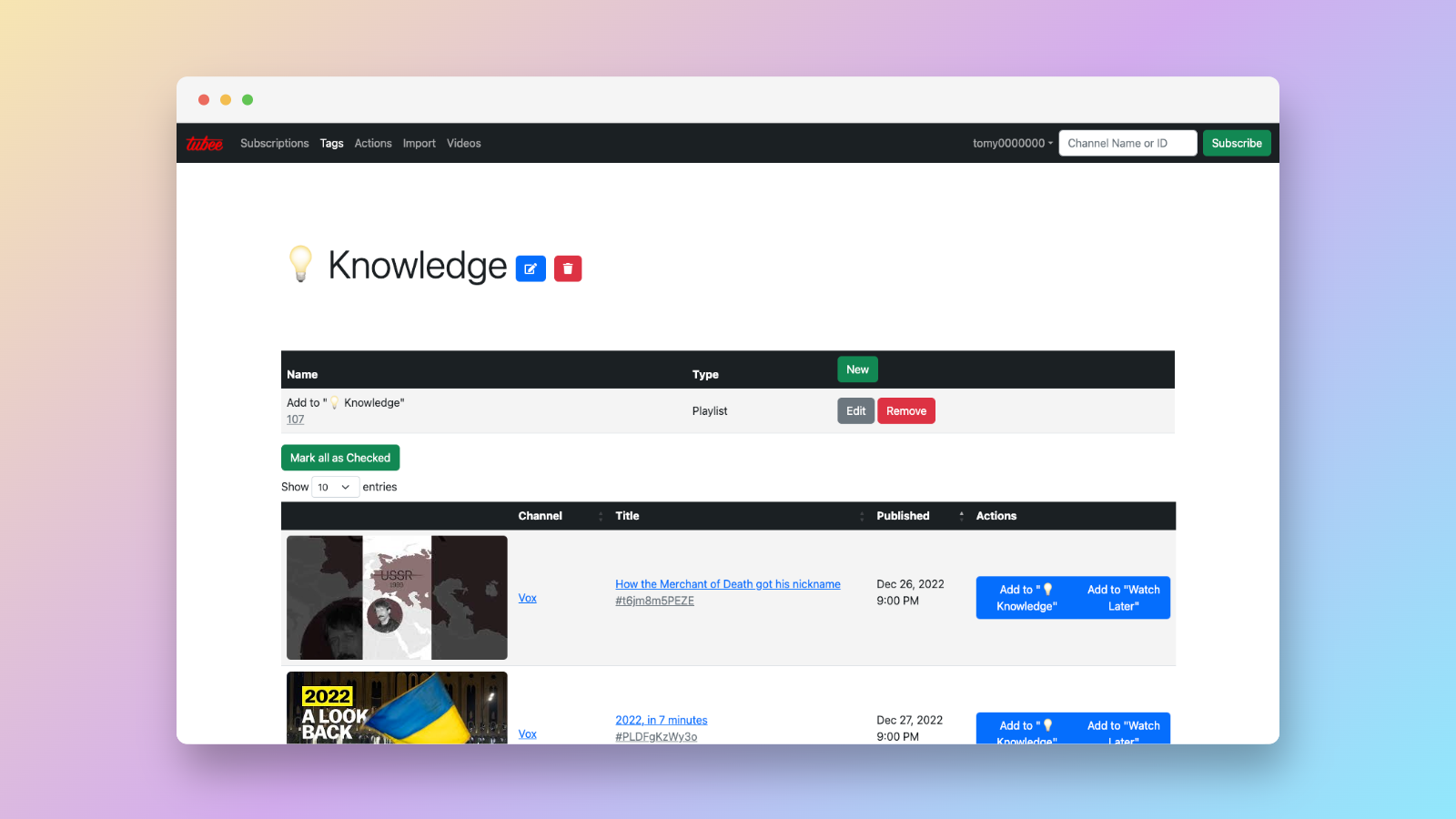
The result was Tubee: a comprehensive YouTube content tracking platform.

Following the blue path, users subscribe to YouTube channels on Tubee just like they would on YouTube (of course, subscription import exists). The background celery worker will consolidate required channel metadatas in the background (The green path). Finally, users can then define “Actions” that execute automatically when new videos are uploaded, which are denoted by the red path. There are three types of actions:
- Add to playlist on YouTube
- Push notifications via:
- Pushover
- LINE Notify
- Download video to Dropbox
Actions form a generalized framework that can easily integrate with more complex use cases. You can also bind actions to tags attached to subscriptions. For example, I could create an “Add to nonfiction playlist” action tagged as “Non-fiction” and apply it to channels like Half as Interesting and 3Blue1Brown, eliminating the need for individual configuration.
If you’re familiar with IFTTT or n8n, think of this as similar automation but at scale. Most importantly, everything works through webhooks rather than polling, ensuring zero-delay triggers. Notifications often arrived as fast as (or faster than) the official YouTube mobile app.
How it all begins
It was 2017, and I was still a CS sophomore. After spending my freshman year writing “basic” CS homework and dozens of tiny one-off tools, I wanted to move on to actually “building” something—a project challenging enough to push my skills and useful enough that I’d want to use it myself.
A friend mentioned that Google Cloud was offering free compute engine credits, and GitHub Student provided additional perks like free domains and developer tools. That covered the infrastructure needs.
Off We Go
From my freshman web programming course, I had basic knowledge of HTTP concepts, HTML, CSS, JavaScript, PHP, and jQuery. I started with a simple “hello world” website and deployed it to a remote server. Since I preferred Python over PHP, I found this DigitalOcean tutorial that helped me set up the stack I wanted.
My development workflow was… unconventional:
- Edit Python source code using Transmit (an SFTP client) and Sublime Text
- Save changes, which Transmit automatically synced to the server
- SSH into the server in another terminal
- Run
sudo systemctl restart apache2to test changes - Backup? Just zip the entire project as
tuber-20180315.zipand call it a day
And Boooom! I was now a “Full-stack Python Web Application engineer”… or so I thought.
Through divide-and-conquer, I gradually worked toward my goal, albeit slowly. Here are some key milestones I achieved:
- Learning how to use git (guess why 🙃)
- Center align a
<div>(byfloating it) - Understand “DevOps”, and set up Travis CI1
- Receive YouTube notification by facilitating the PubSubHubbub protocol. 2
- Witnessing the sunrise shine on my screen
- Authenticate with YouTube Data API using OAuth 2.0 (took me like, a week?)
- Containerization with Docker and Docker compose, surprisingly not difficult
It was countless nights of trial and error, programming and debugging, and an awful lot of bad technical decisions—like changing the web server from Apache to nginx without even a clear reason.
More often than not, I found myself starting somewhere trying to achieve one thing, but ending up diving deep into something I never anticipated—for instance, reading through all ssl_ciphers available in nginx.3
Expansion
After fulfilling the initial requirements, I moved on to experimenting with other engineering aspects of software projects after reading more and more engineering blogs.
Even though I didn’t implement all of them perfectly, here are some of my key takeaways from hindsight:
- Figure out at least ~85% of the requirements first, before making architectural decisions. Changing requirements is one of the biggest risks a software project may encounter, potentially making the end product beyond repair.
- Avoiding refactoring is nearly impossible. Even predicting what might change is difficult. However, breaking down your functions and components and following SRP will make your life a lot easier.
- Documentation skills take time to develop, just like writing a good resume. Some of the best documentation I’ve read includes FastAPI, Docusaurus, and Resend.
On the other hand, there were also more technical advancements, developed from natural requirements, such as:
- Logging, and I mean “structured logging”, that allows searching and matching.
- User authentication, and learning basic security principles to protect user information.
- Staging environment, so I don’t always mess up production during deployment.
Many years later, I learned that these are all part of the Twelve-factor app methodology, and I somehow achieved many of these principles without knowing they existed ¯\_(ツ)_/¯
At this point, I felt like my hard-earned skills were well developed and practically useful for building production-grade applications. Why should I bother with theoretical CS knowledge that barely exists in the real world… right?
A case deep dive
Circling back to the existing architecture, upon startup, Tubee would loop through all subscribed channels and sign up for notifications for new videos. Since subscriptions only last for five days, I had to re-subscribe every five days. That’s where I brought in APScheduler, a crontab-like background worker module which does exactly that.
I plugged it in, made it work locally, and shipped the feature to production, crossing my fingers, only to discover a peculiar issue: The logs showed that every job I set up was running multiple times when invoked, instead of just once.
Even though this wasn’t a big issue for my use case (re-subscribing five times wouldn’t hurt), I took this as a challenge.
At first glance, I thought I must have messed something up. Maybe the logger was misconfigured? Was I logging multiple times? But wait! I had fully tested this in development, and everything went smoothly, which meant something must be wrong in production. It turns out that Gunicorn4, the WSGI server I was using, follows a pre-fork model. This means that even though there were barely any requests, it spawns multiple workers to handle incoming requests. APScheduler gets initialized in each worker and executes jobs multiple times.
This is where the journey became rough. I started by looking for a way to define “custom initialization” that could set up the master process with APScheduler and skip it for worker processes, but this failed. I then looked for methods that would allow workers to communicate with each other (inter-process communication) and figured out a way to initialize only one APScheduler instance among them—the notorious “leader election” problem. This never really worked.
It wasn’t until I finally gave up after (literally) months of trying that I decided I should seek help from the community for the first time. I posted this Stack Overflow question which drew little to no attention, because I was terrible at phrasing and clearly articulating my question.
But guess what—I was fortunately helped by two pivotal people. The first was Alex, the author of APScheduler, who was so kind and helpful that our discussion became almost like a one-on-one project consultancy session, answering the long-standing question that had stumped me for so long. A few days later, Miguel, author of “Flask Web Development,” also pointed me in the same direction.
It turns out that if I had grasped the basics of distributed systems, I would have immediately known that supporting modules like APScheduler should have been their own component from the start, and the nightmare I encountered wouldn’t have been an issue at all.
Lessons learned:
- Seek help early. In my experience, a problem that persists over two to three long breaks is typically a good sign that you should seek help.
- Foundational knowledge is equally important and should be treated as invisible technical debt. This is especially true if your goal is to become a true full-stack developer or engineer.
Sunset
At peak, I tracked ~250 YouTube channel and process 600+ new videos per day, but that’s the furthest it ever gets.
A few months later, as I shifted my focus towards research projects at the NLP Lab, I gradually lost time to put much effort into Tubee. Even more, I also didn’t have time to watch all the YouTube videos I was interested in at all.
Having less spare time was merely a fact that led to the end of the project. The underlying real issue, however, was that the foundation of this requirement wasn’t concrete enough. The problem statement of
Solving the algorithm bias by re-introducing the chronologically-ordered video feed
…never held up, and here’s why it failed:
- It failed to draw my attention. It may be a feature, not a bug in some sense, but this is just how it works naturally.
- It doesn’t scale. People have limited time; scrolling through all subscribed uploads makes no sense.
- It doesn’t encourage exploration. Why try new channels when you can barely finish your existing watch list?
Ultimately, it failed to solve a real-world problem for the end user (ironically, myself).
As the requirements faded away, so did the development. At the time of writing, I’m officially declaring the death of my first side project, but deep down I know it has been dead for a very long time.
Circling back to the original question:
Does YouTube strategically mute notifications, to prevent causing attention fatigue?
Well, not much evidence was found. There are cases where content creators upload videos and later take them down within a short time. People who haven’t been notified may not receive notifications, and some might have their notifications rescinded. But “deliberately” silencing notifications? Not that I could find.
Reflections
Now that it’s gone (for what it’s worth), I’d like to reflect on what I probably could (or should) have done differently:
- Share it / Collaborate: Even though I never intended to make the service public, I don’t think I ever demoed it to anyone—not my family, not my friends, not anyone.5 This significantly reduced my chances of receiving feedback, both technical and product-wise.
- Move faster, Break more things: I think I read this early in the project and always kept it in mind, but I felt like I never really understood or achieved this. Perhaps what really drives this is having collaborators working on the same project.
- Wear different hats: Being the sole contributor to the entire project meant I had to handle roadmapping, design, implementation, testing, and feedback for every feature. The difficult part wasn’t doing all of these, but separating myself from working on all of them at once. It wasn’t until recently that I learned I should wear different hats and act in different roles for specific periods of time.
So yep, this post is my first attempt at sharing my project and experience with the public.
Last few words
Nevertheless, I gained a few crucial traits from this experience.
It’s only been a couple of years since AI coding became the new norm, and I’ve almost forgotten what it’s like to debug without AI assistance—working through problems with Google searches, reading Stack Overflow, and most importantly, paging through documentation.
Although not as often as I used to, I still enjoy reading excellent documentation. There are wonderful tutorials out there that go way beyond just explaining how things work. They’re like reading a story that recounts the past, explains the why, and reveals how something came to be. Building knowledge and understanding around core concepts develops the ability to reason about behavior and usage, and perhaps how things will evolve. Hence: “A great engineer knows their tools.”
It’s also the mindset of boundaryless exploration that I embraced, which accumulated considerable invisible technical capital that comes in handy for new projects and even at work. I’m confident enough to predict:
Talent that can RTFM and work through Stack Overflow and GitHub issues will become the next scarce resource in the tech job market over the coming decades.
Remember, GitHub Actions wasn’t a thing until 2019. ↩︎
I’m surprised that this is still the way a web service subscribes to YouTube channel, in 2025. ↩︎
Don’t try this at home, especially if you’re allergic to math. Just use NGINXConfig and call it a day. ↩︎
Notice I changed my WSGI server here? Again, another example of changing the tech stack for absolutely no reason. 🙃 ↩︎
Funny to say, Tubee had a built-in, bullet-proof user authentication system with just two registered users: me and someone at Google responsible for auditing YouTube Data API usage. ↩︎